I’ve been a Drake fan since 2009 when I first heard “Best I Ever Had” from So Far Gone. Over the last decade, I’ve watched Drake transform into a global rap and pop superstar. This weekend I saw Drake live in Brooklyn as part of the Aubrey & the Three Migos tour. What better way to celebrate than by analyzing his catalog using Spotify’s API? I’ve broken the celebration into two parts, getting the data and analyzing the data. Click here if you’d rather skip the code and jump into the analysis.
Getting the Data
In this post, I use Spotipy, “a lightweight Python library for the Spotify Web API”. Let’s start by calling the necessary libraries.
Next, we need to authenticate and connect to the API. To do so, we need a “client id” and “client secret”. To obtain them, visit the Spotify Developer Dashboard here and create an application. In the code snippet below, replace the client id and client secret variables with your own.
There are a few potential ways to create a dataset of Drake’s catalog. We could have first obtained a list of the artist’s albums and then looped through each album track. Instead, I used a playlist by ‘100 percent’ which claims to have, “all of Drake, all in one place.” This collection of 219 songs (15+ hours) contains “every appearance currently on Spotify updated with each new release.” Great! We’ll now write a function to retrieve the ids for each track of this playlist.
With the list of track ids, we can now loop over each id and obtain track information such as track name, album, release date, length, and popularity. More importantly, Spotify’s API allows us to extract a number of “audio features” such as danceability, energy, instrumentalness, and tempo. Without going into how these measures are determined, we’ll use them to understand how Drake’s style has evolved over time.
We’ll now loop over the tracks, applying the function, and save the dataset to a .csv file.
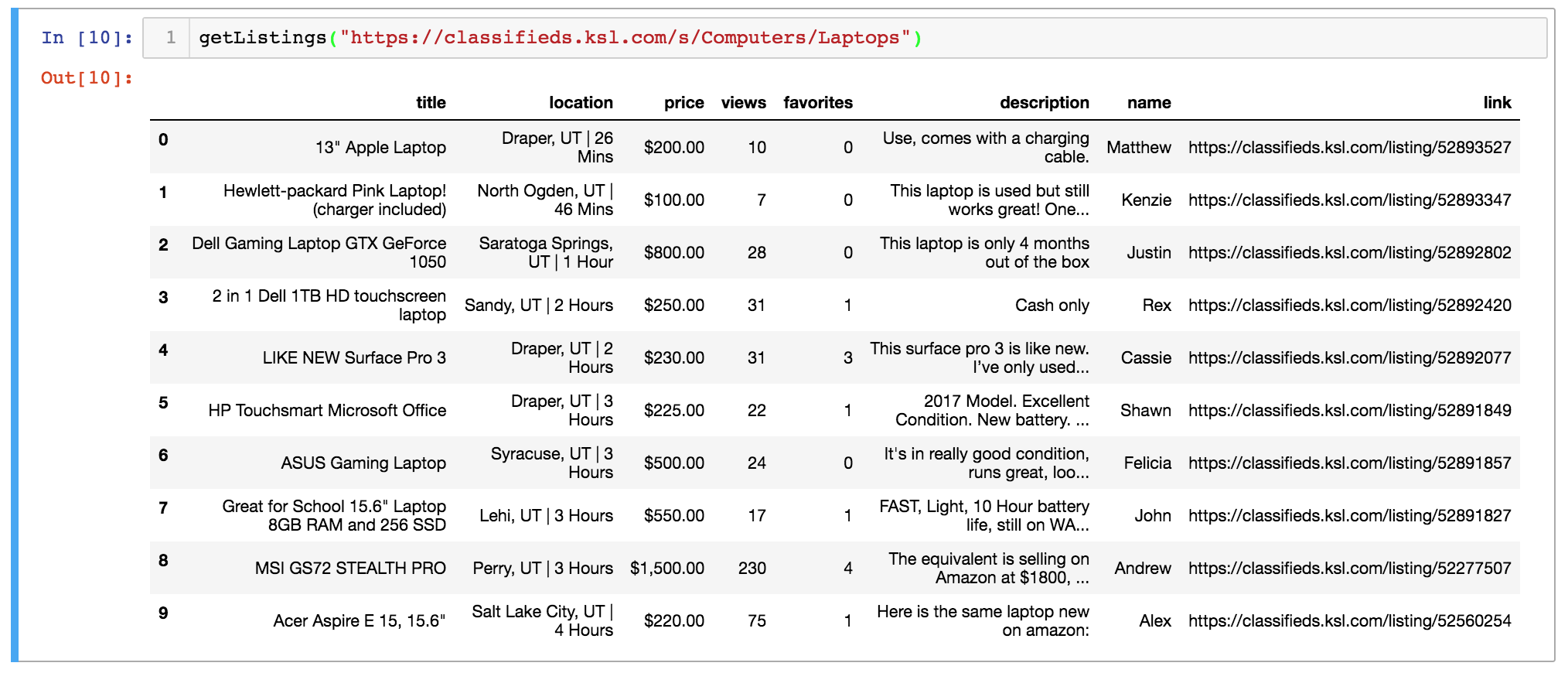
Here’s what the raw dataset looks like:
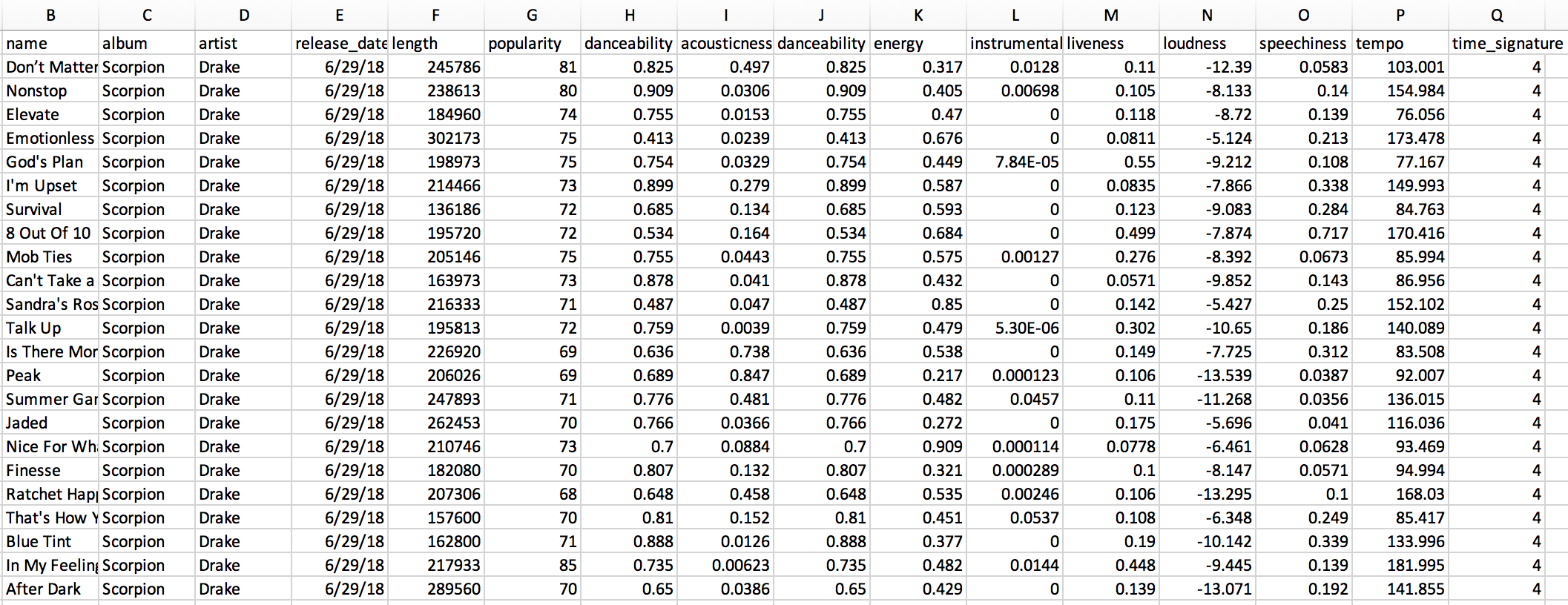
You can find the complete script to obtain this data here or download the dataset here.
Analyzing the Data
Let’s quickly clean a few variables in preparation for analysis. We’ll first convert the song length from milliseconds to minutes. Second, since the artist field captured the principal song artist, let’s create a boolean variable called “feature” which indicates whether or not Drake is the principal artist. Let’s also create a “year” variable using the release date for easy aggregation and grouping. Finally, we’ll reference the Drake discography Wikipedia page to create a “type” variable to distinguish between singles, extended plays (EP), mixtapes, studio albums, and feature tracks.
And now for some analysis. To begin, I’ve embedded a Tableau worksheet below which provides an overview of each Drake song for four core measurements: danceability, energy, speechiness, and tempo.
This worksheet allows you to filter by type and to highlight a track within that type. I’d recommend clicking on the “expand” symbol in the lower right-hand corner for a better look.
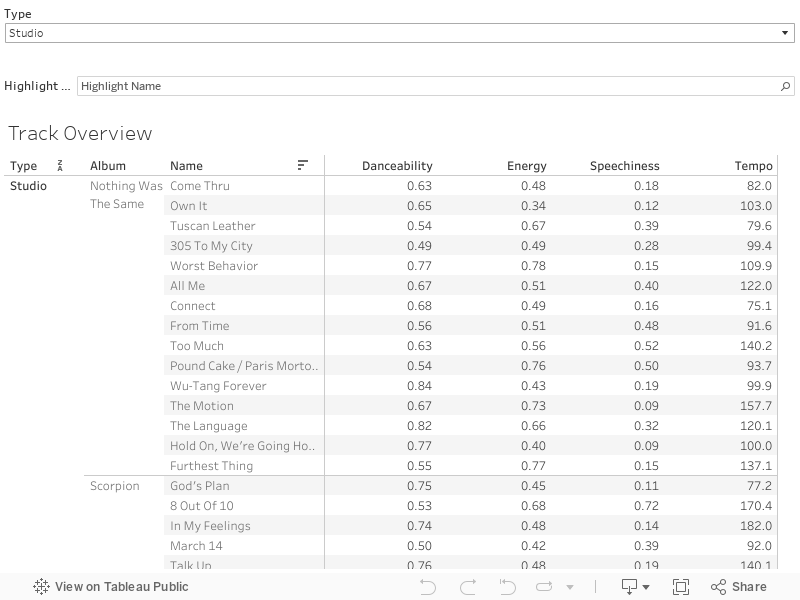
A quick description of these four audio features, from the Spotify API Endpoint Reference:
Danceability: Describes how suitable a track is for dancing based on a combination of musical elements including tempo, rhythm stability, beat strength, and overall regularity. A value of 0.0 is least danceable and 1.0 is most danceable.
Energy: A measure from 0.0 to 1.0 and represents a perceptual measure of intensity and activity. Typically, energetic tracks feel fast, loud, and noisy. For example, death metal has high energy, while a Bach prelude scores low on the scale.
Speechiness: Detects the presence of spoken words in a track. The more exclusively speech-like the recording (talk show, audiobook, poetry), the closer to 1.0 the attribute value. Values between 0.33 and 0.66 describe tracks that may contain both music and speech, either in sections or layered, including such cases as rap music.
Tempo: The overall estimated tempo of a track in beats per minute (BPM).
Tracks Over Time
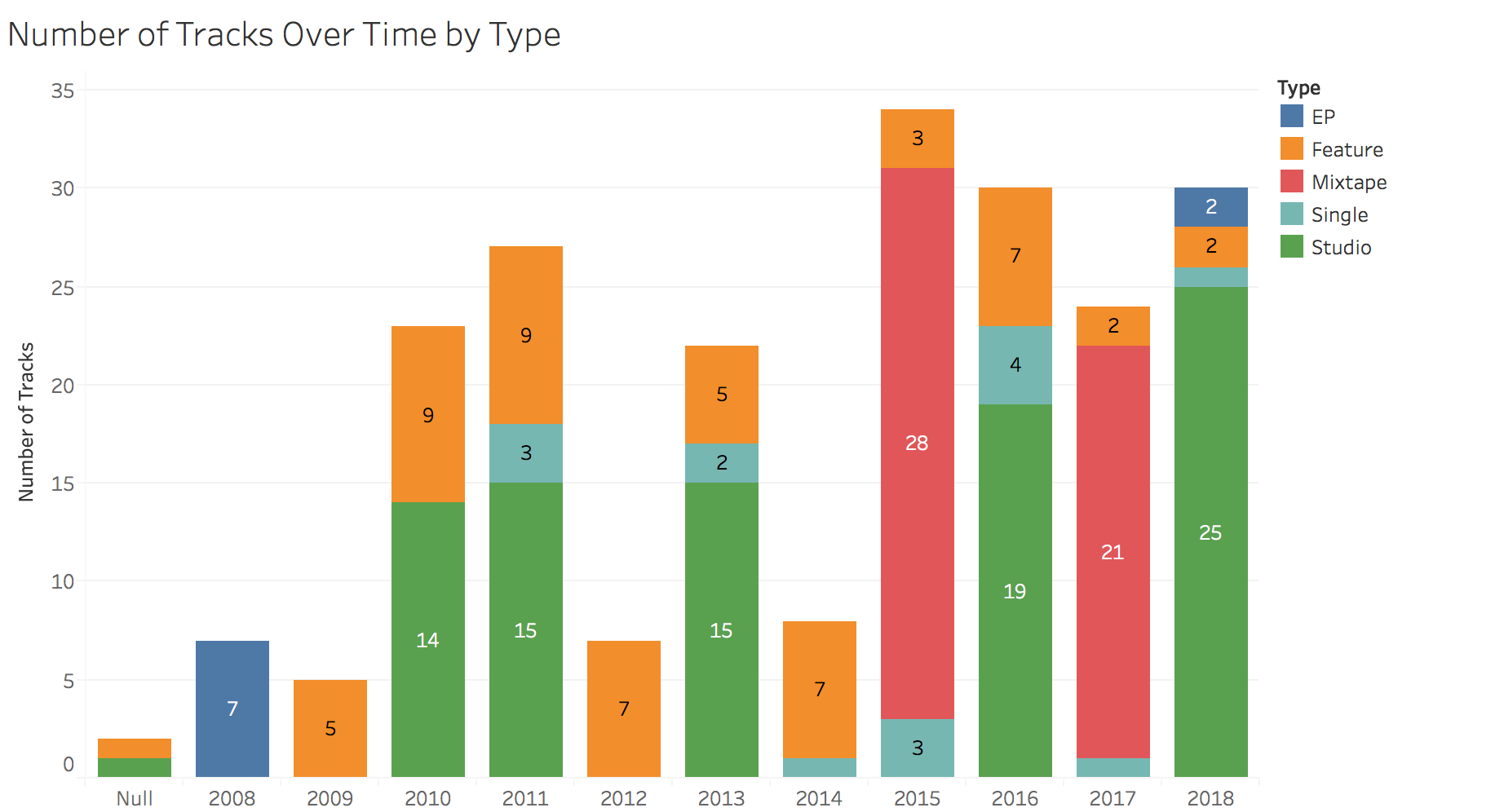
With those definitions clarified, let’s move onto a few visualizations. We’ll start with the number of tracks over time.
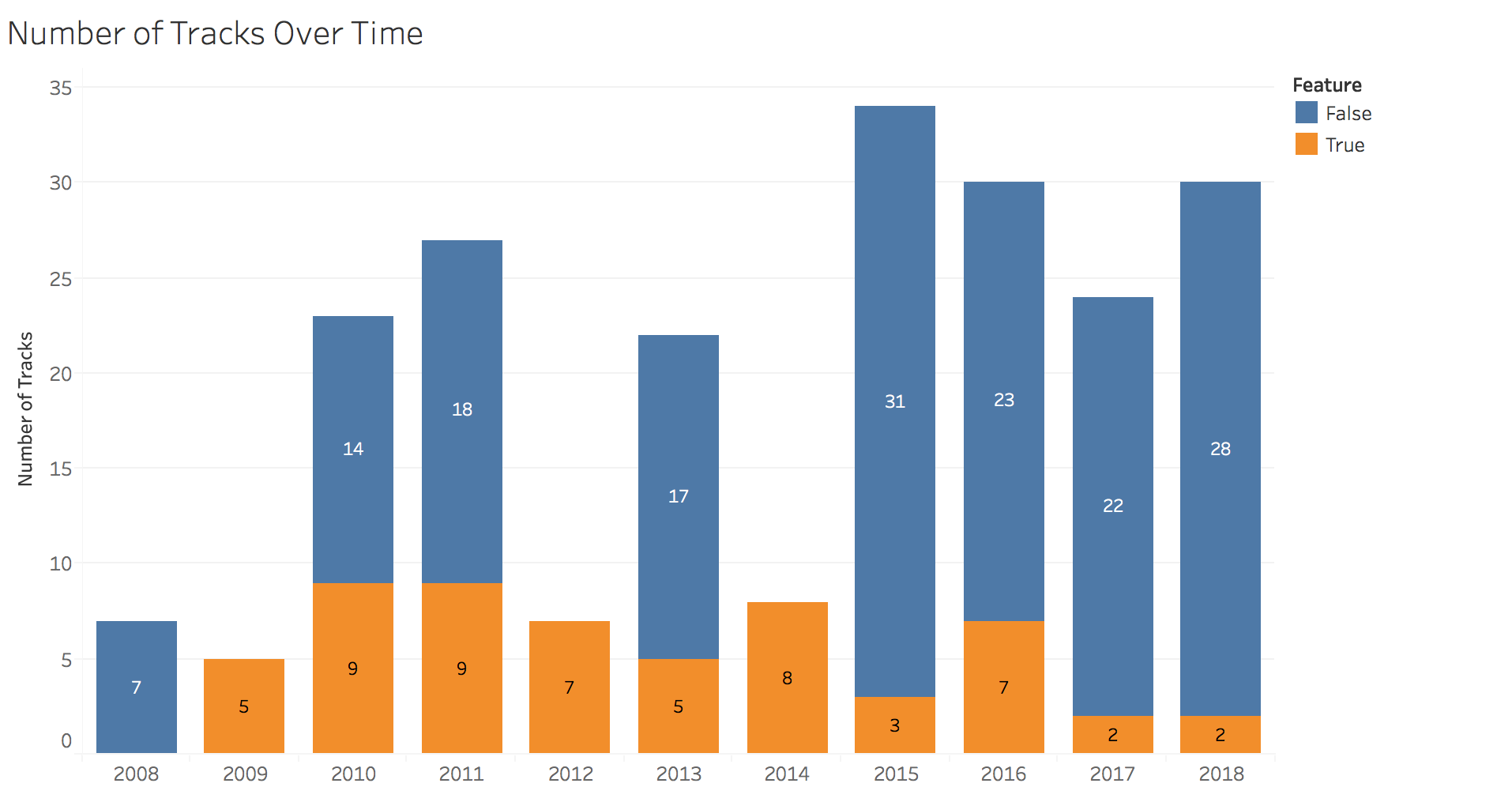
In this chart, we see that Drake has provided fans a fairly constant stream of new jams since 2008. In 2012 and 2014, Drake only jumped onto other artists’ song, releasing none of his own. In 2015, Drake blessed us with a doubleheader: If You’re Reading This It’s Too Late and What a Time to Be Alive plus additional singles and features for a total of 34 songs.
This can be seen more clearly in the next chart:
Track Length
I recently read a Pitchfork article (highly recommended, great visualizations) that analyzed the length of hip-hop records over the last 30 years. Drake is notorious for long albums, with his latest double-sided project coming in just under 90 minutes. Keeping in mind that there may be a strategic, streaming-oriented purpose, let’s take a look at how both album length and song length have trended over time.

The answer to the question posed in that Pitchfork article, “Are Rap Albums Really Getting Longer?” is abundantly clear here, at least in Drake’s case. His five studio albums have each progressively become longer. Some might call this a blessing, others a curse. What about average track length?
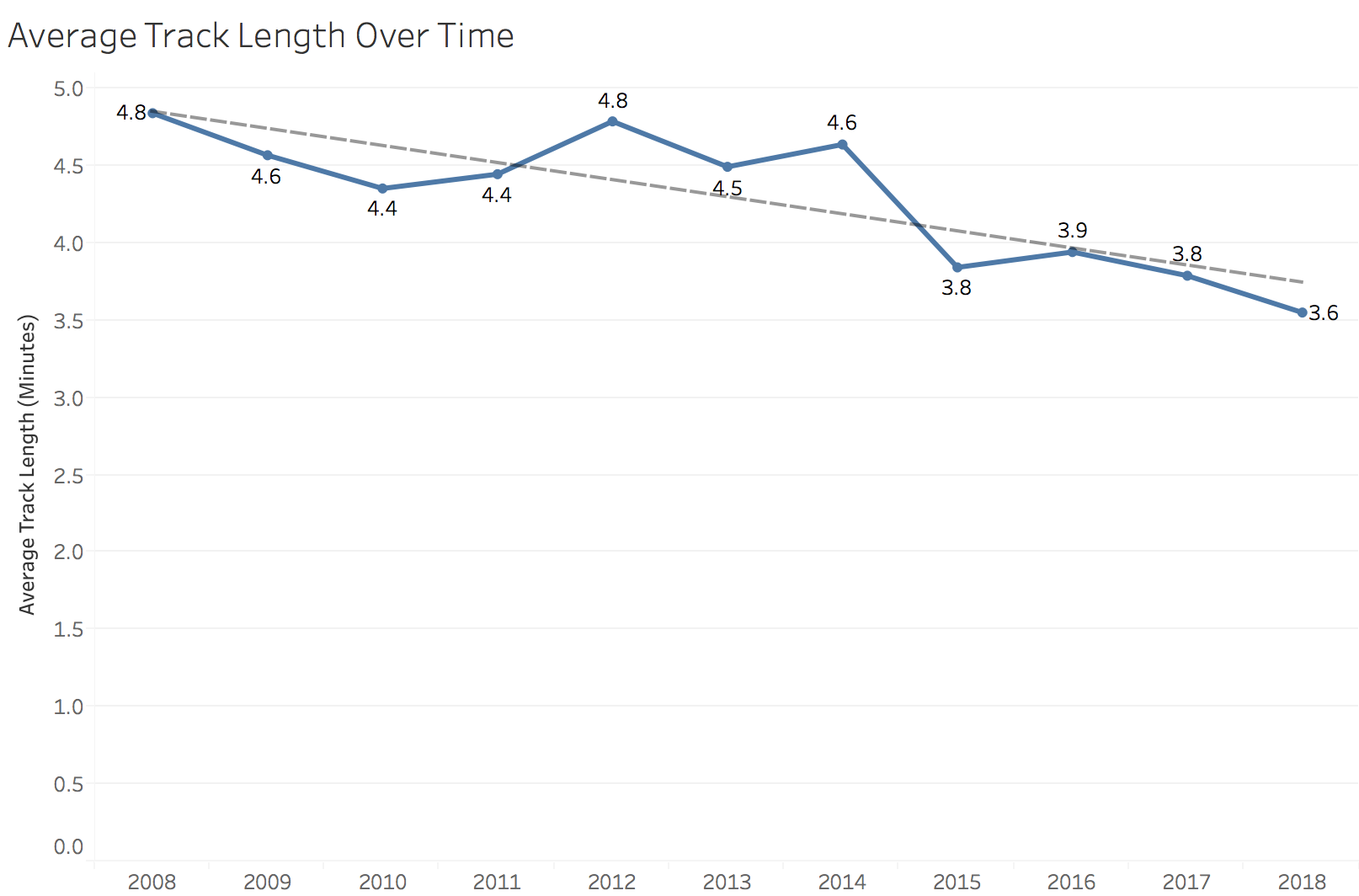
While Drake’s albums appear to be getting longer, his songs are, on average, getting shorter. Over the past decade, average song length has decreased more than a minute, from 4.8 minutes in 2008 to 3.6 minutes in 2018. Maybe this is another effect of the transition to streaming, as music streaming is now the industry’s biggest revenue source.
Danceability & Energy
It’s pretty common for artists to “go pop” on the road to wider reach and popularity. Measuring the danceability metric for Drake’s songs over time might be a good way to test for a shift towards pop appeal. Shown below is average danceability and energy over time.
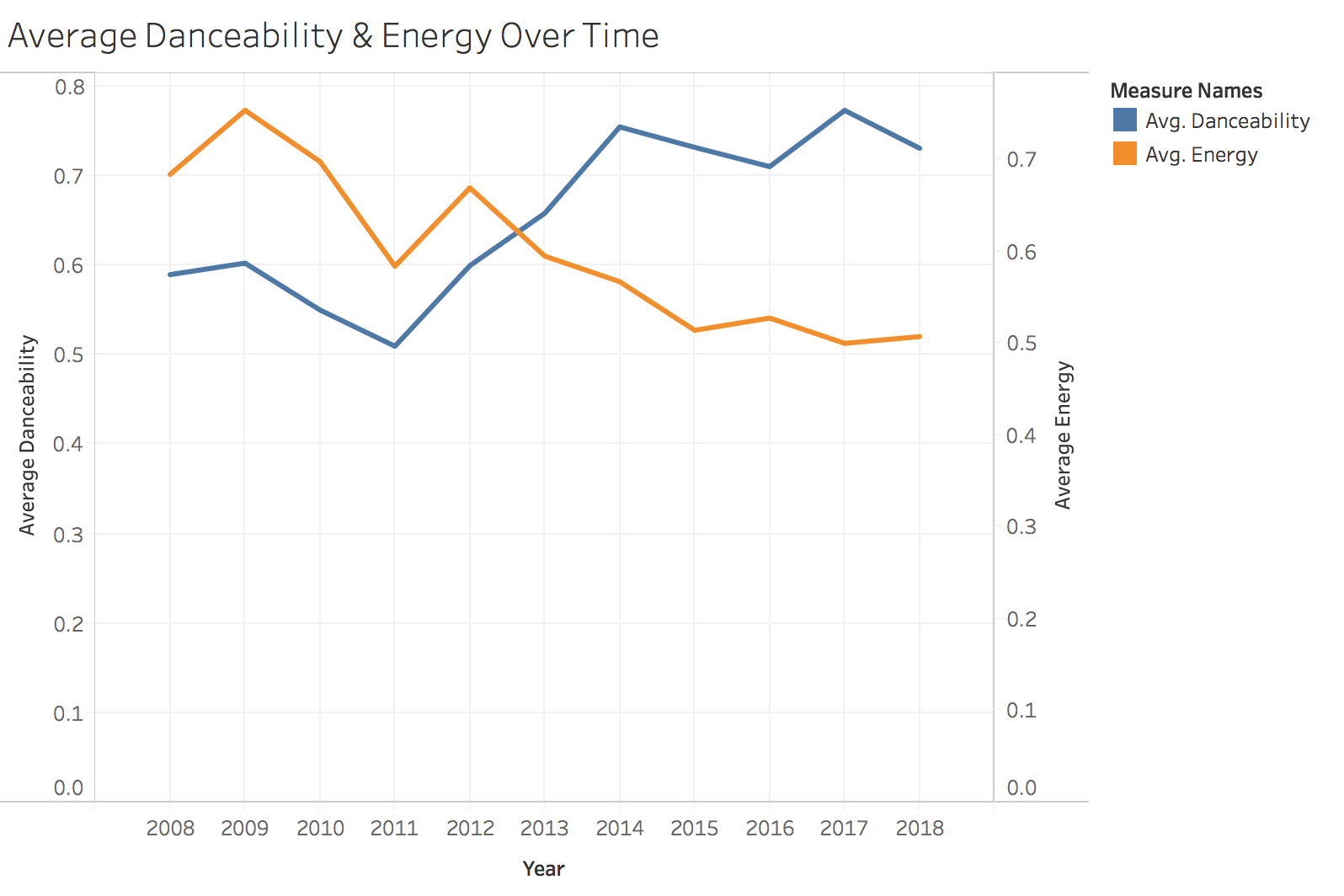
There’s a pretty clear upward trend in danceability, with a simultaneous decline in energy.
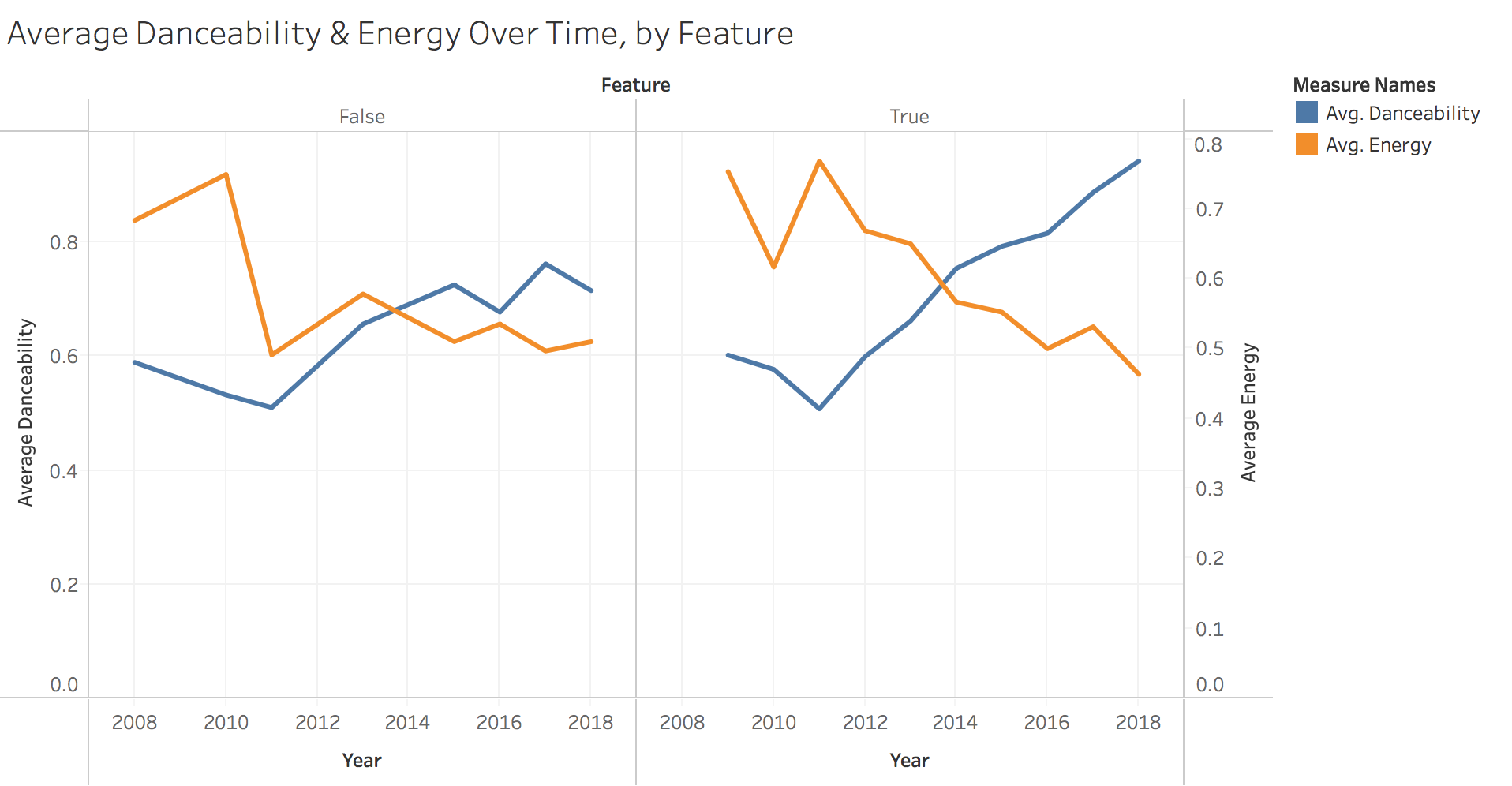
This holds true when we separate songs Drake is featured on versus his own, but his more pronounced on featured songs.
Top Collaborators
Finally, who does Drake like to work with? Here we measure the number of features by artist.
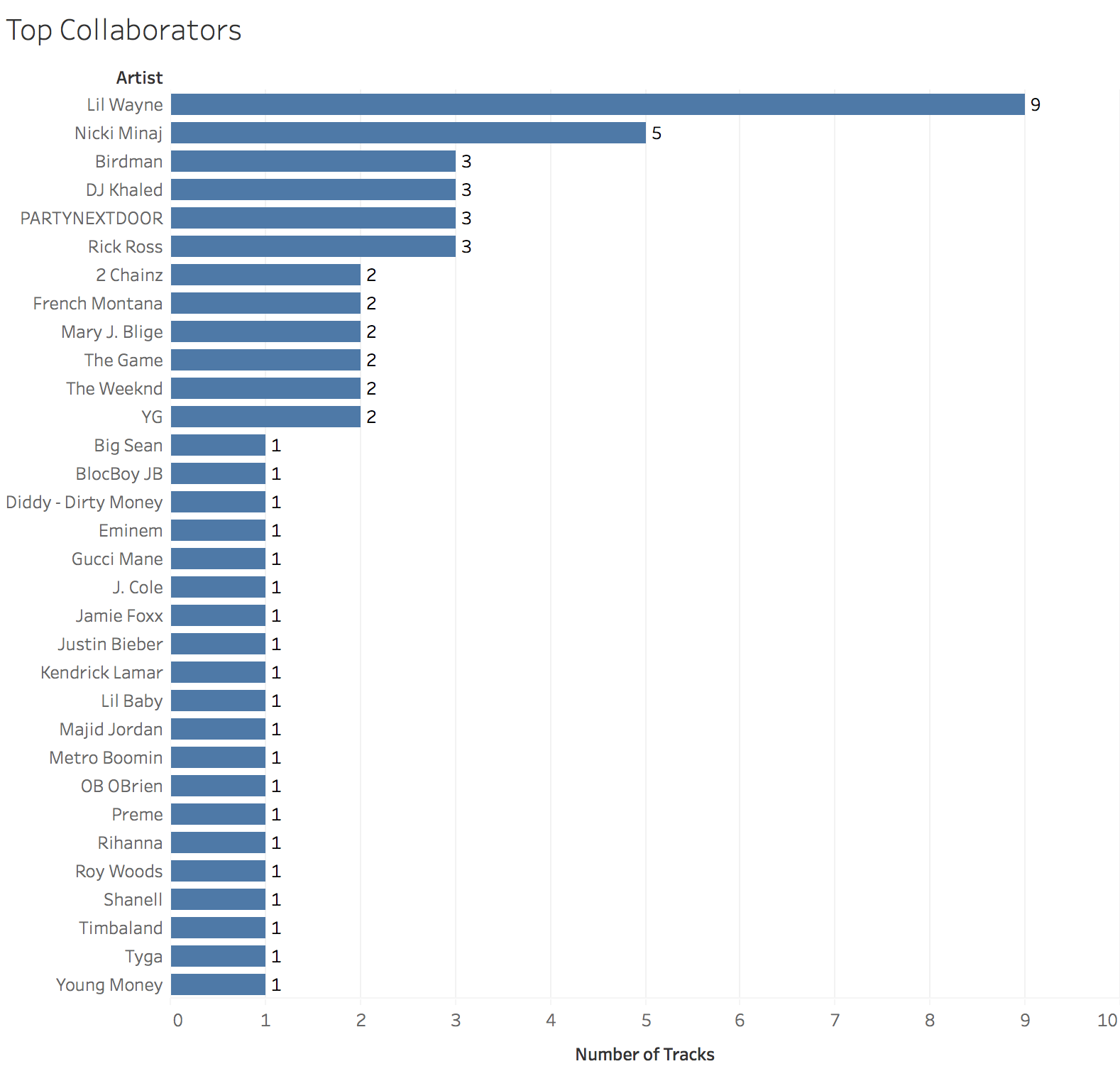
The top three artists are all current or former Young Money acts. Beyond that, it’s clear Drake has worked with artists across a large spectrum of rap and R&B artists, from Rick Ross to Jaime Foxx.
Conclusion
APIs can be a great source of unique and interesting datasets. In addition to the information presented here, I’d be interested in expanding the dataset to include song recording location, principal producer, lyrical content, and the number of streams the track has obtained.
You can find the full, interactive version of the Tableau charts here and the dataset here.