Today it feels like rap is bigger and more mainstream than ever. A casual scan of the charts reveals that many of today’s biggest music icons are rappers. How long has it been this way? I remember a time when pop legends like Katy Perry, Lady Gaga, and Rihanna ruled the charts.
Looking for more than anecdotal evidence of the rise of rap as a genre in the mainstream music landscape, I developed a data-driven methodology to measure the high-level trend in music genre popularity over time.
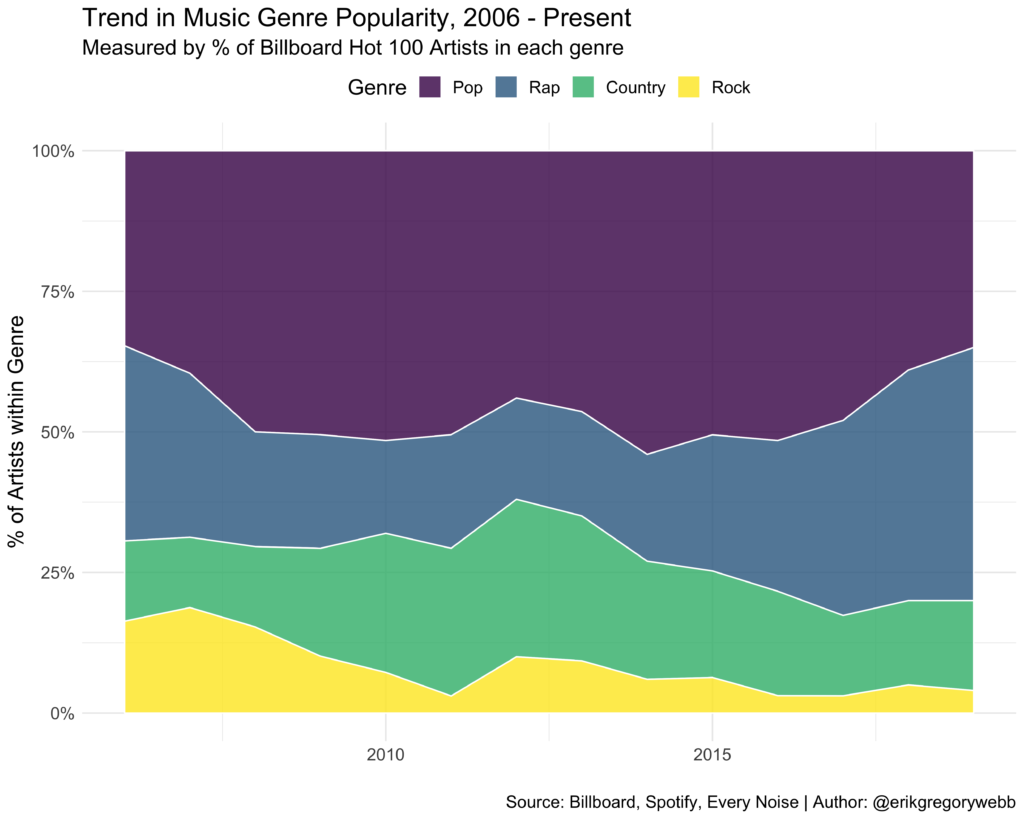
Using Billboard’s Hot 100 Artist data, and mapping each artist to a genre using the Spotify API, I calculated what percent of the artists were represented within each genre over time, from 2006 to the present.
Here’s the trend:
Here’s another view with the same data, as a line chart:
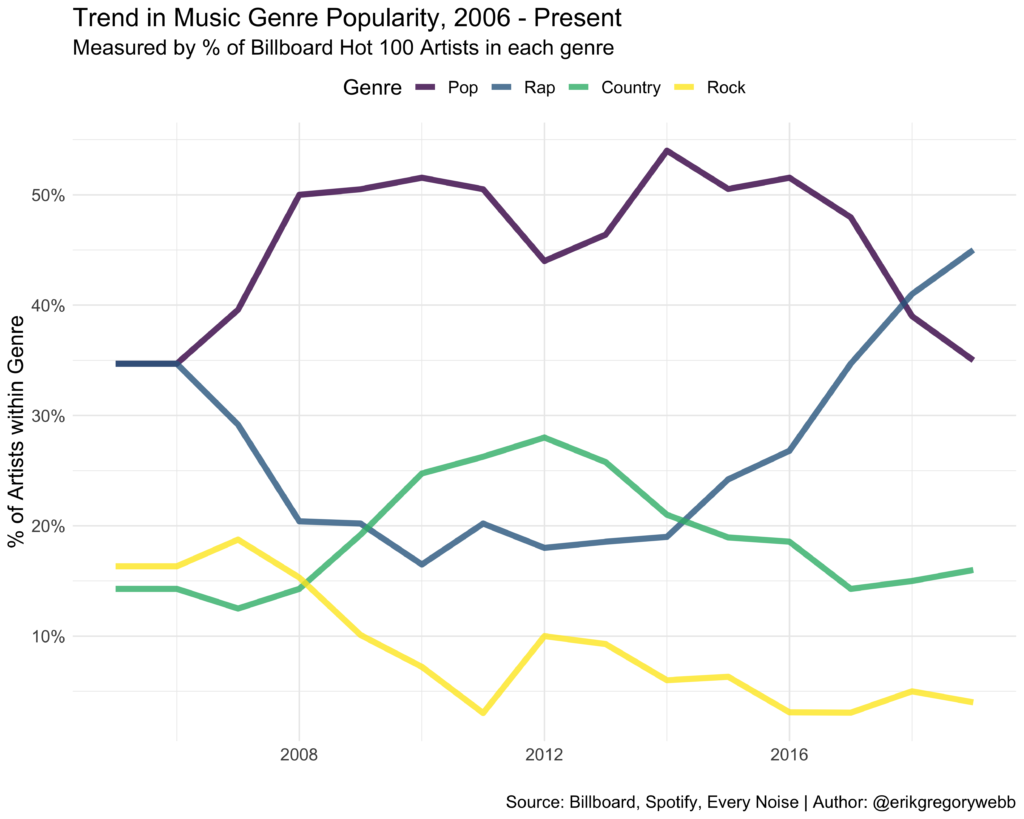
It seems like the data supports my observation that rap has gone mainstream, with the percentage of rap artists in the Billboard Hot 100 growing steadily since 2014, and surpassing pop artists in 2018.
According to Rolling Stone, much of rap’s growth can be attributed to its reactivity on streaming services, with 92% of the genre’s total consumption coming from streaming channels. The timeline fits, with streaming giants like Apple launching in 2015, and Spotify hitting ~40 MAU in 2016.
While pop and country have maintained a relatively stable level of popularity, rock appears to be trending down, with rock artists composing less than 5% of the Billboard Hot 100 artist list in 2019.
What does the future hold? As the lines between genres continue to blur, with artists like Post Malone and Lil Nas X cutting across pop, rap, country, and even rock, it stops making sense to box artists into a single genre. In the age of the playlist, it’s easier than ever to rebel against the very idea of genre.
Walkthrough
The first step of the project was scraping the historical list of Hot 100 Artists from Billboard. Using the tidyverse and rvest packages in R, I quickly looped over the 13 years of available data:
Below is a preview of the first few rows of the resulting dataset:
Next, using a Python script and the Spotify API, I looped through each of the artists from the Billboard Hot 100 dataset and collected a list of their corresponding sub-genres. For example, Spotify associates Sean Paul with the sub-genres of dance pop, dance hall, and pop rap.
Here’s a preview of what the resulting data looks like:
The next step took some thought. I needed a way to map back each of the thousands of sub-genres labeled by Spotify into a few core genres, like pop, rap, country, and rock. Tapping into the work of the Every Noise project, which attempts to create “an algorithmically-generated, readability-adjusted scatter-plot of the musical genre-space”, I developed logic to assign a single genre to each of the artists in the original Billboard Hot 100 artist table:
Using this logic, each artist was assigned to a single genre bucket:
The last step was to merge the billboard artist and artist genre tables and calculate the genre percentage breakdown over time, from 2006 to 2019.
This R code produces the chart below that visualizes relative genre popularity over time:
You can find the GitHub repo for this project here.