
Introduction
I recently listed a couple of items for sale on a Craigslist-like site called KSL Classifieds. It’s a rich marketplace to buy and sell almost anything. This is what a listing looks like:
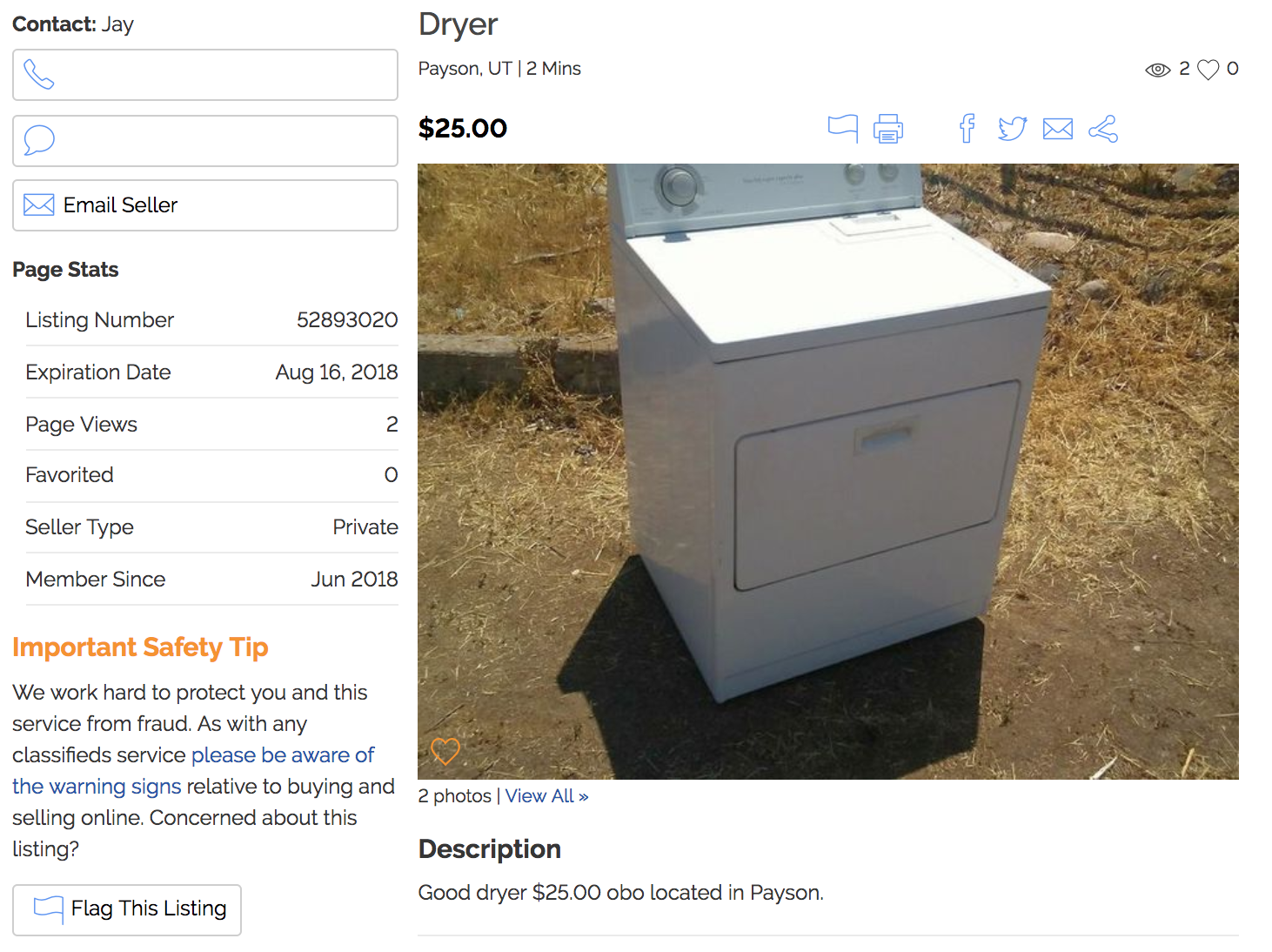
I instinctively started thinking about how to collect information about listings in this marketplace in a systematic way. Why might this kind of autotomized data collection be valuable? Here are two possible use cases:
- Listing optimization. We could analyze how features of a listing (number of pictures, description length, listing category/subcategory, etc.) are related to outcomes such as the number of views, if the item is “favorited” by users, or whether or not the item was sold. This kind of data-driven listing optimization could drive sales for sellers.
- Automated Item Search. There’s value for buyers as well. Suppose I’m looking for something specific, like a wakeboard for family boating outings. I could easily automate a script to scrape all wakeboard listings daily and send me the information via email, simplifying the search process.
Walkthrough
Let’s jump into the walkthrough. At a high level, we know we want our web scraping script to take a KSL Classified URL as input and output a CSV containing neatly-arranged data from each listing. Here’s what the starting page might look like:
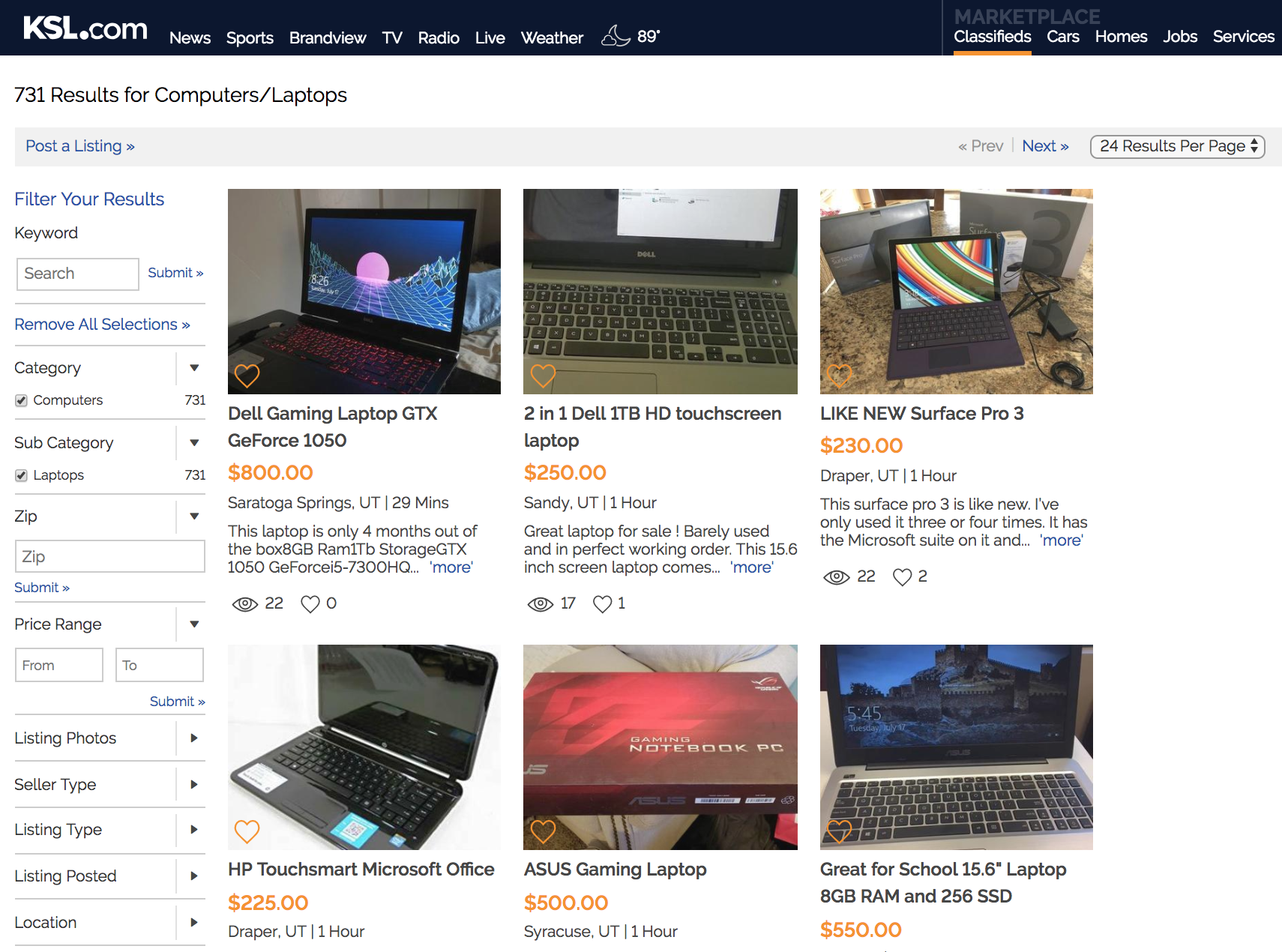
Given this page, we need to find all the links to listings, navigate to each listing page, and then extract the desired information. Each listing contains the following features:
- Title
- Location (City, State)
- Time Posted
- Price
- Number of Views
- Number of Favorites
- Description
- Seller Information
With that as background, let’s get into the code. We’ll start by calling the libraries.
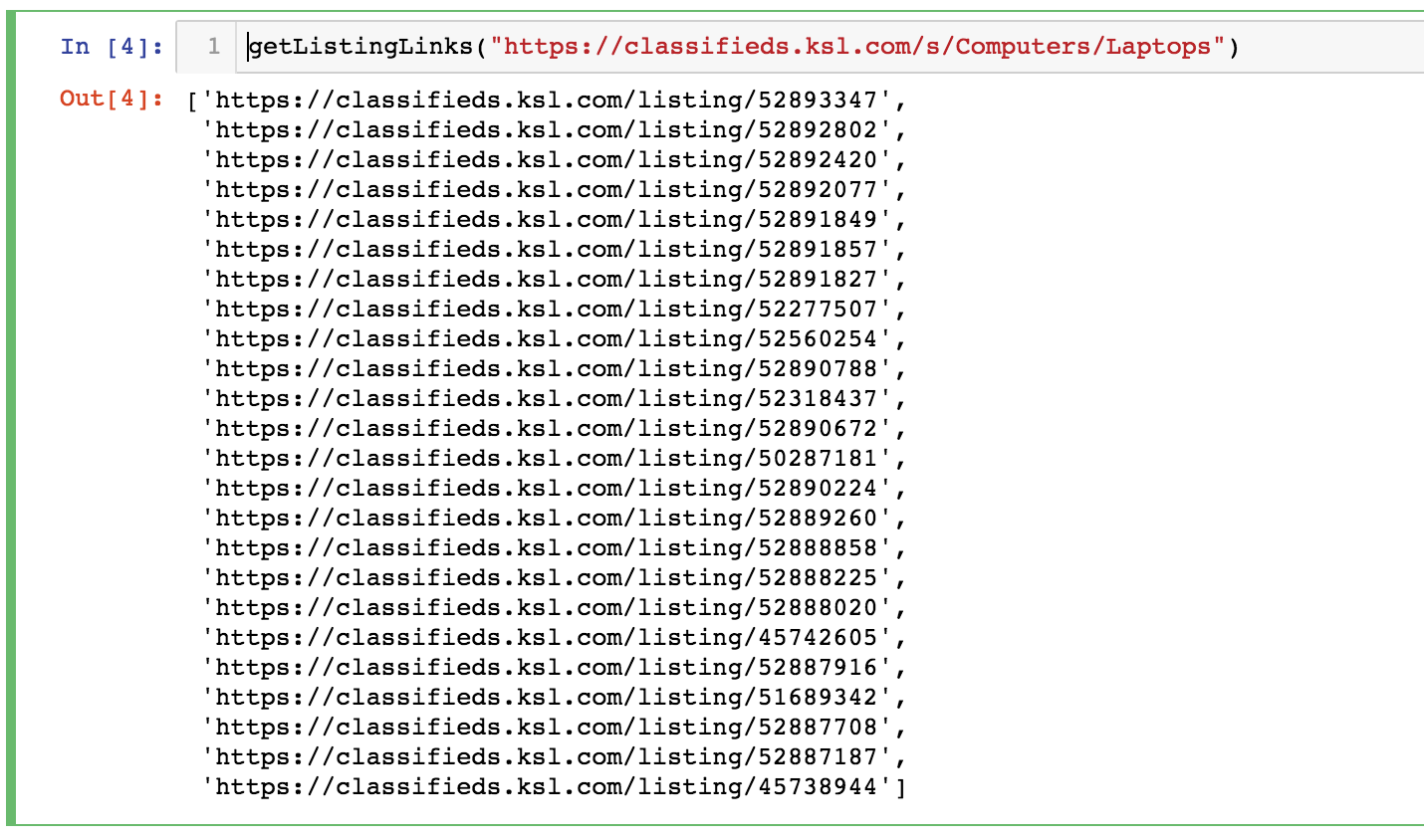
Next, we’ll write a function to extract all the listing links from a search result page like the one above.
Note that I’m using “ChromeDriver”. It can be downloaded here. Below is what the output of our function looks like. We now have a vector of links to specific listings.
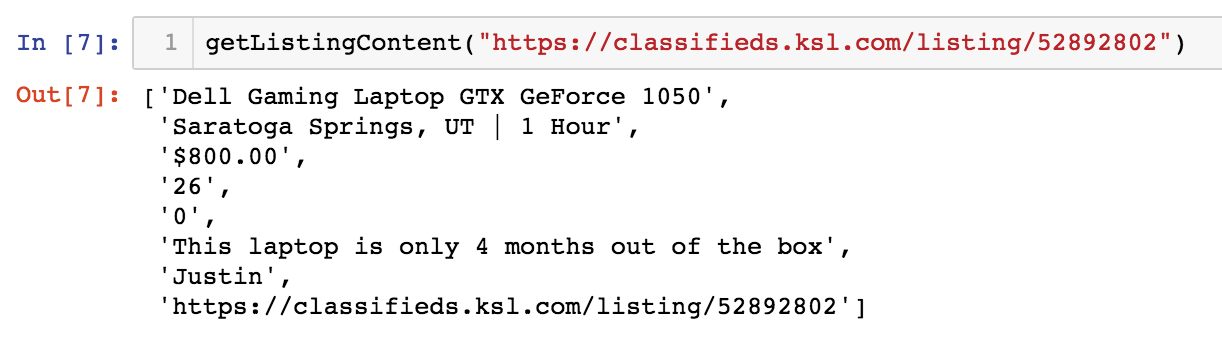
 Now we need to iterate through each of these listings and extract the desired information. Below is a function called getListingContent() which takes a listing link and return the title, location, time since listing posting, price, views, favorites, description, seller, and the listing URL.
Now we need to iterate through each of these listings and extract the desired information. Below is a function called getListingContent() which takes a listing link and return the title, location, time since listing posting, price, views, favorites, description, seller, and the listing URL.
Again, here’s what the output of this function would look like:
Pretty slick eh? Now let’s combine these two functions!
Here we’re only going to loop through the first ten of the listing links gathered by getListingLinks(). After the loop, we’ll neatly arrange the extracted data into a Pandas DataFrame.
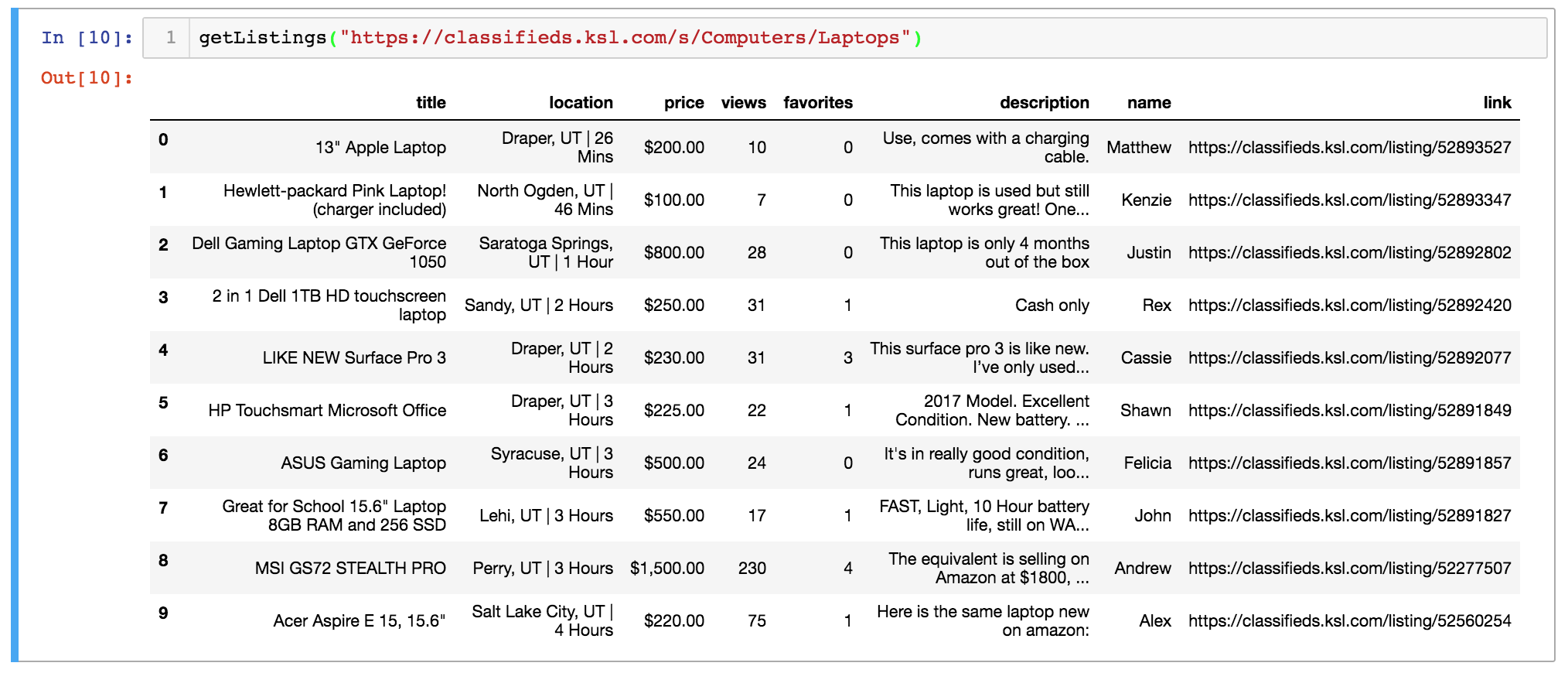
To finish things off, we’ll clean the data. This includes reformatting the “price” variable and changing “views” and “favorites” from strings to numbers.
Finally, let’s tie it all together with the main() function:
Nice work! We can now pass a link to main() and it will generate a tidy CSV file with information about the listing from that page. You can find the complete scraper code here. Below are some resources that proved helpful to me in creating this example:
that’s slick af