I recently discovered a salary calculator on Stack Overflow. The tool takes inputs like role, location, and education and outputs salary predictions at the 25th, 50th, and 75th percentile.
Based on the results of the annual developer survey, the calculator seems like an interesting way to study the marginal impact of expereince and education on earnings. As a recent undergraduate, I might be interested in understanding the impact of graduate degrees on income potential.
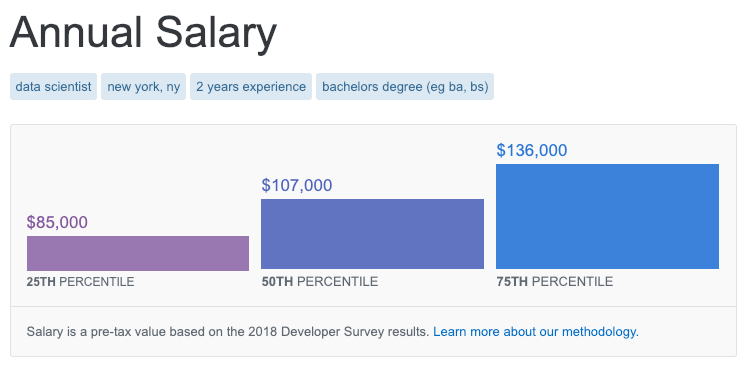
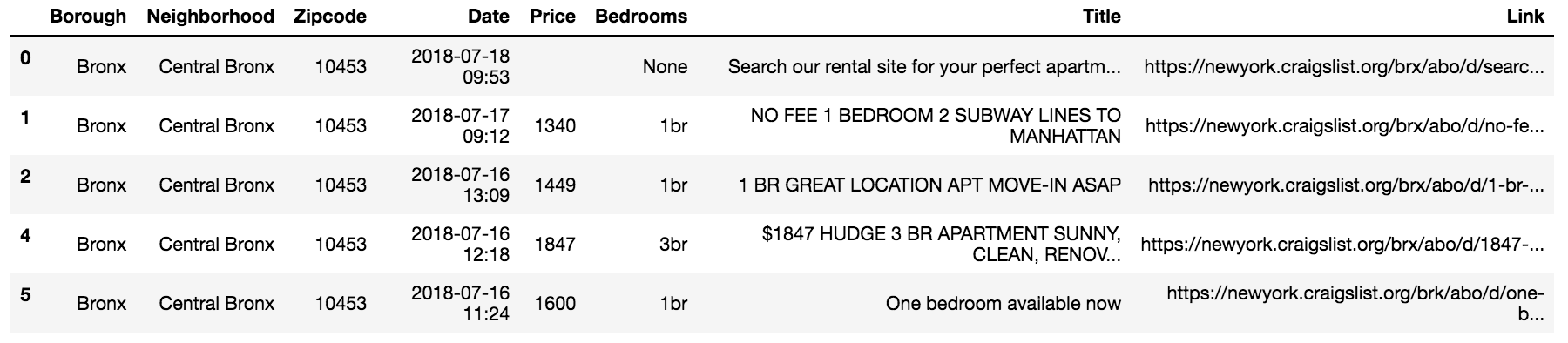
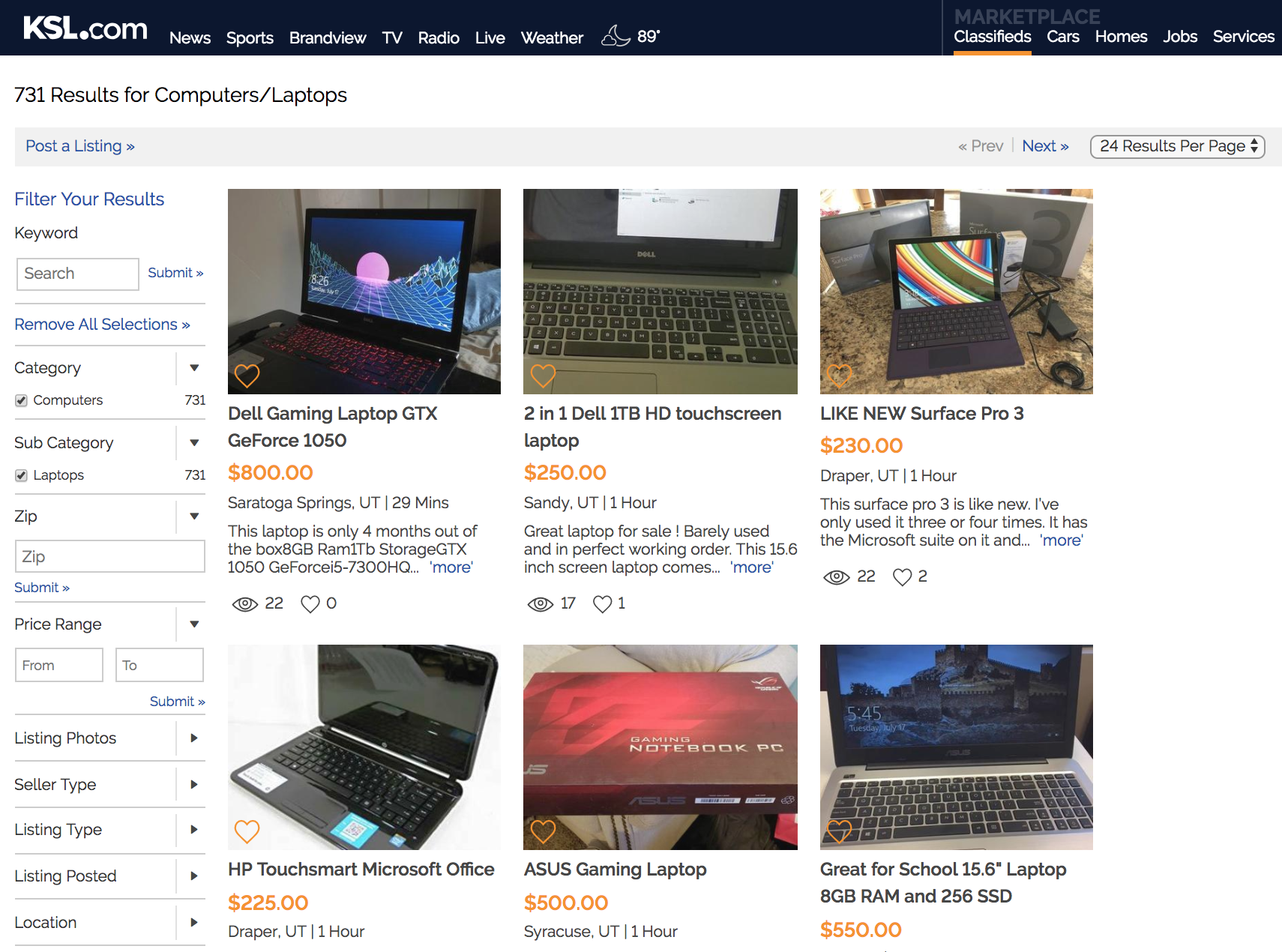
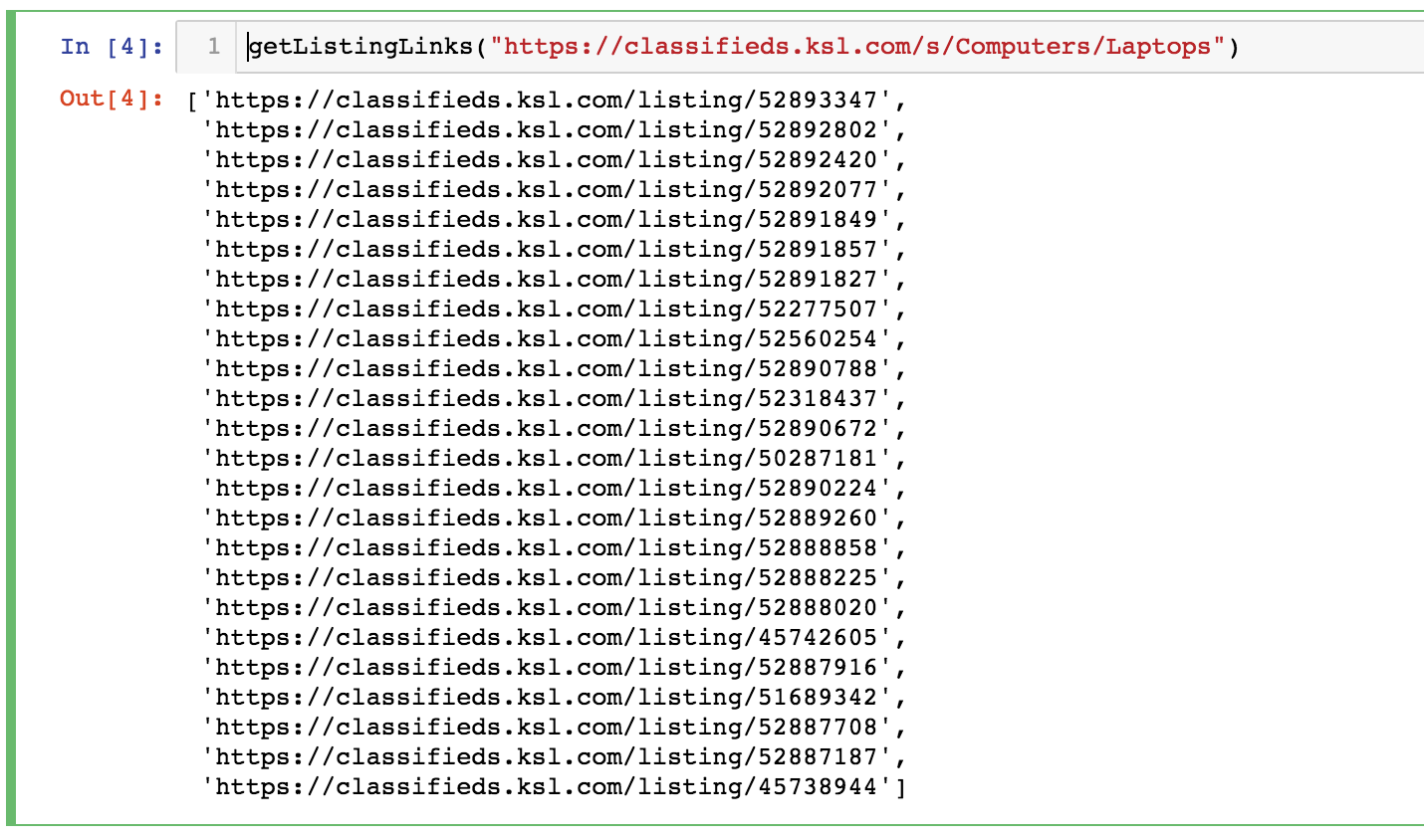
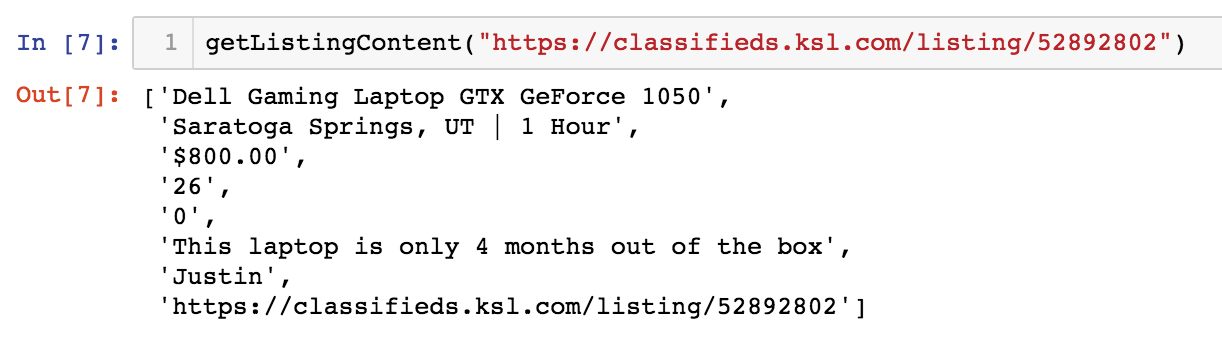
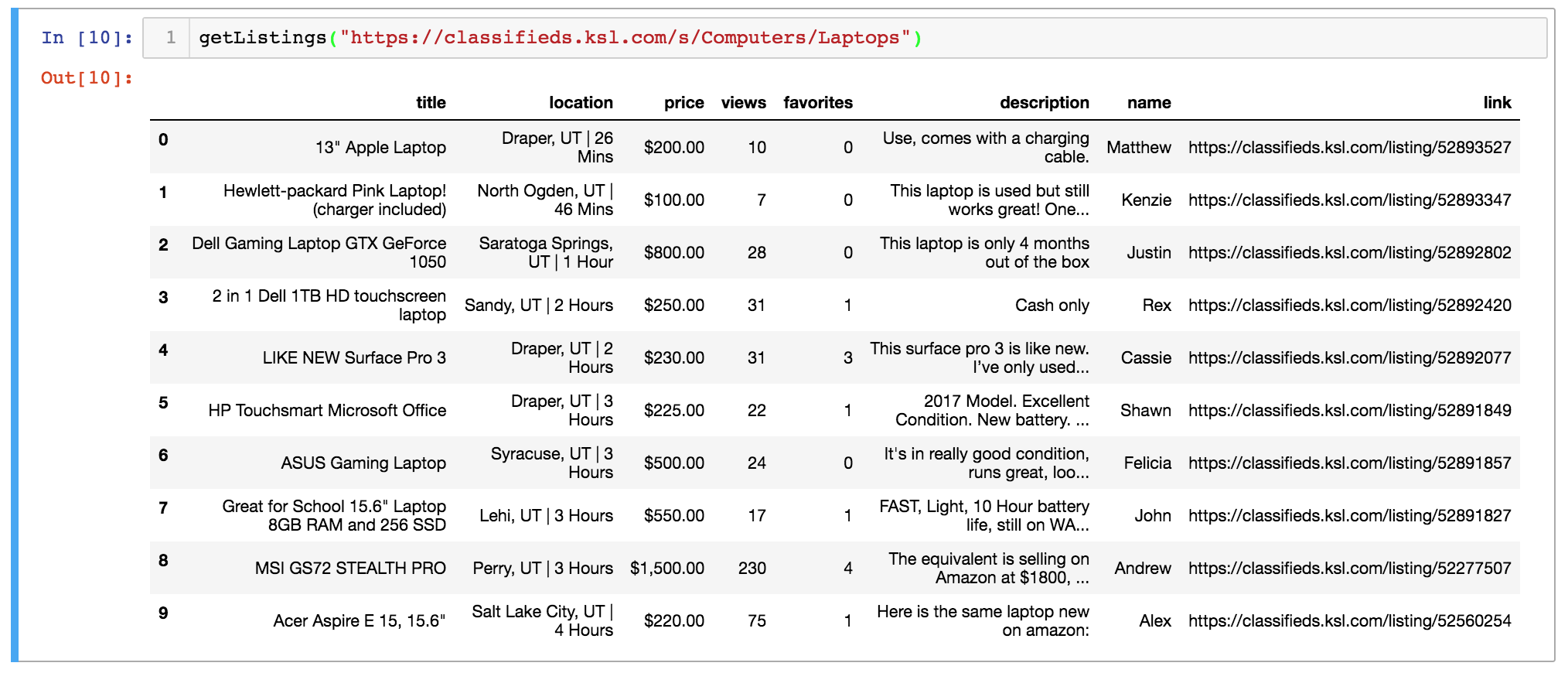
To extract Data Scientist salary data (or extrapolated data) from the tool, I wrote a Python script using Selenium to loop through 350+ different combinations of location, education and expereince.
Results
There are many reasons to exercise skepticism when analyzing this data, like self-selection bias inherent to surveys. It’s obviously very unlikely that a data scientist responded from each location, education, and experience combination. Even if they did, salaries are likely to vary widely. To strengthen any insight derived from this analysis, I’d also collect data from sources like Glassdoor or Indeed, especially before making any significant education or relocation decisions!
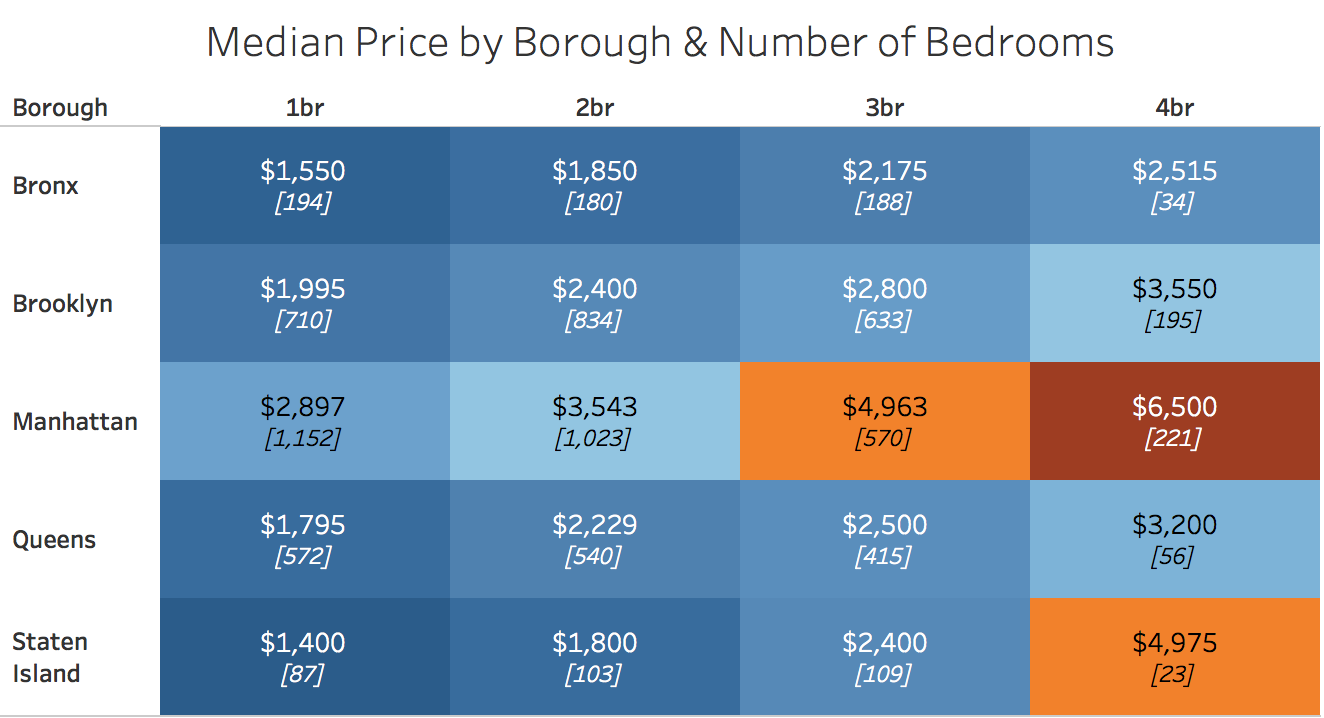
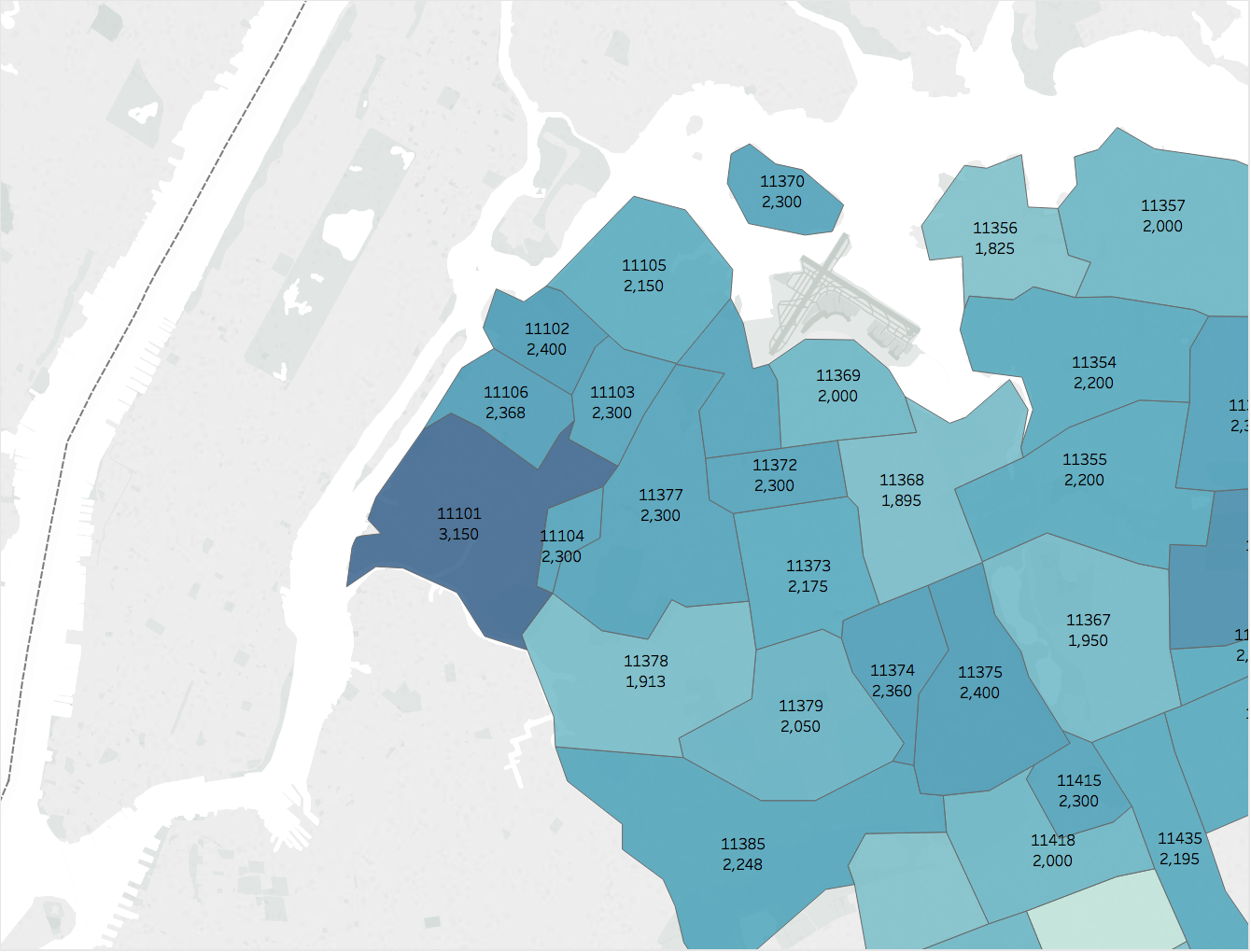
With that long disclaimer in mind, below I visualize the scraped data with an interactive Tableau dashboard. You can filter by years of expereince and location to understand salary levels by education level:
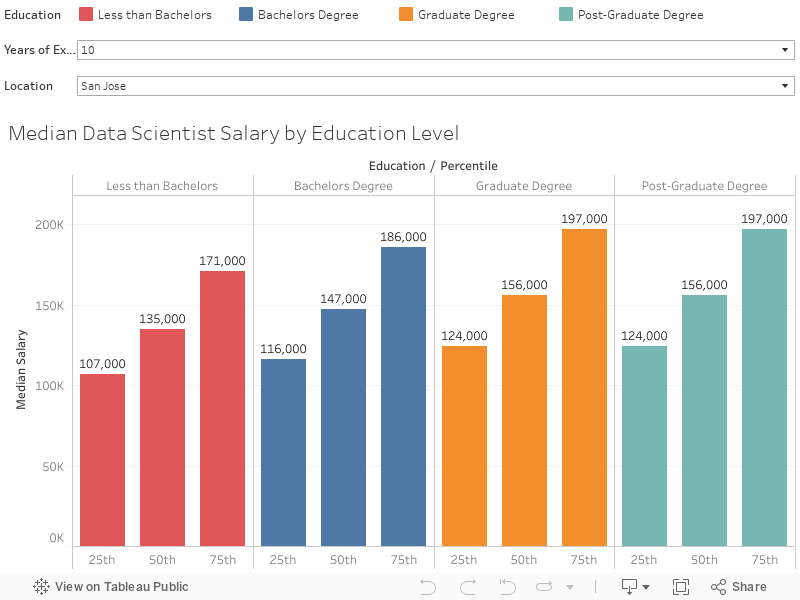
One disappointment I had was realizing that much of the data returned from the calculator was the same across locations. The same salaries were also returned across expereince and education levels for graduate and postgraduate degrees. Despite the data shortcomings, this was an interesting exercise in automating data extract from web forums using Selenium. Thanks for reading!
Appendix
Python Script: Link
R Script: Link
Dataset: Link
Tableau Dashboard: Link