Public by default, your Venmo transactions are surprisingly accessible to anyone with an internet connection. Although Venmo has removed functionality to query historical transactions, it’s public API still provides a real-time snapshot view of transactions processed through the system, including usernames and payment subjects (though not the amount sent or received). Try it for yourself here.
With that said, it was straight-forward to collect a bit of data from this API using R. The bulk of the script was needed to parse the JSON file returned by the API to extract interesting information. In this post, I’ll highlight sample data from the API in an effort to expose the kind of information being openly shared. If you use Venmo, follow these instructions to change your transactions to private by default.
Sample Data
Using the API, I collected data from 1,250 payments. From
each of these transactions, I was able to view the following information:
- Payment Id
- Payment Date, Time
- Payment Message
- Sender & Receiver Name, Username
- Sender & Receiver Profile Photo
- Sender & Receiver Venmo Account Creation Date
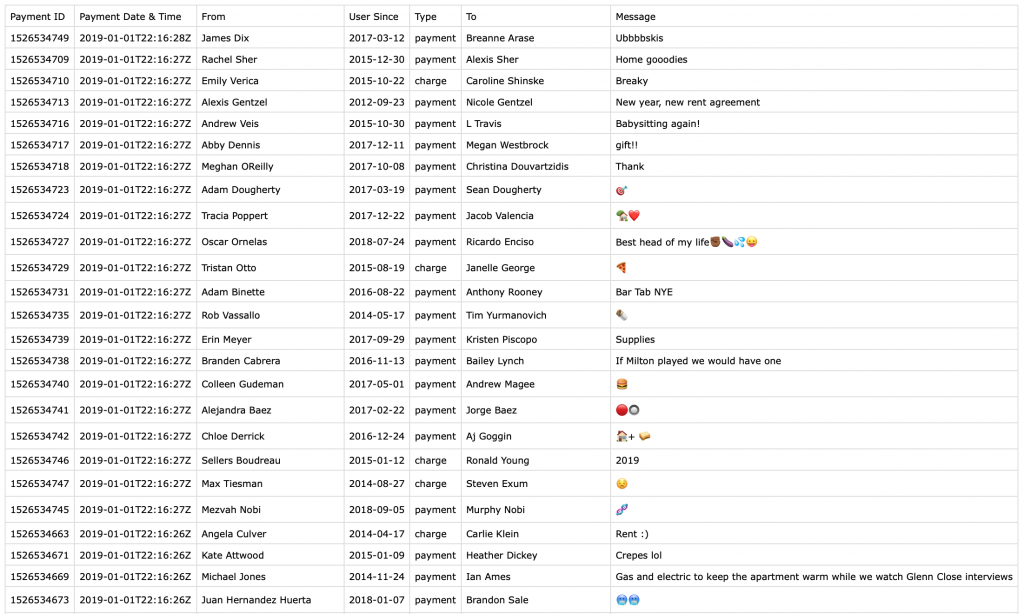
For example, on January 1, 2019 Scott Perkinson sent Patrick Miller an undisclosed payment for “Caroline Bachelorette Party & Wine tasting”. That same day, Kerry McCarthy paid Anna McCarthy for “Barbie dream house furniture.” You can’t make this stuff up.
Bottom line, privacy is important, and you should take any available steps to limit how your information is shared. If you use Venmo, start by making your payments private by default. You can find the datasets I compiled here and the R code to access the API here.